엔비디아의 GPU 로드맵에 따르면 올해 출시 예정인 칩은 H200, B100, GH200 세 종류로 모두 HBM3E 탑재 예정이었으며, 하반기 Blackwell 아키텍처 출시가 예고되면서 데이터센터향 수요 증가가 예상되었다. 기존 아키텍처인 Hopper와 비교할 때, Blackwell은 아래와 같은 주요 차이점을 지니고 있다.

1) Hopper 4nm 공정에서 Balckwell 3nm 공정노드로 변화
3나노 공정은 4나노 공정에 비해 더 많은 트랜지스터를 동일한 면적에 집적할 수 있다. 트랜지스터는 GPU 내에서 전기신호를 처리하고 제어하는 역할을 수행하므로 그 수는 GPU의 성능과 비례하다. AI 모델이 성장함에 따라 학습에 필요한 메모리 용량이 크게 증가하였고, 이에 따라 칩의 처리 능력을 향상시키기 위해 트랜지스터 수 또한 증가하는 것이다. H100은 약 800억개의 트랜지스터로 구성되어 있는데 반해, B100은 2080억개의 트랜지스터로 구성되어 기존 칩보다 2.5배 빠른 연산 속도와, 최대 30배의 성능 향상을 제공할 수 있을 것으로 예상된다. 또한 3나노는 전력 소비를 약 20-30% 감소시켜 배터리 수명 연장에 기여하며, 칩의 크기를 축소할 수 있다는 장점이 있다.
미세 공정에서의 차이점도 존재한다. TSMC는 3나노 공정에도 4나노 공정에서 사용하는 FinFET(Fin Field-effect transistor) 공정을 적용하였으나, 삼성전자는 3나노 공정에서 GAAFET(Gate all around FET) 공정을 도입하여 사용하고 있다.
소자가 미세화됨에 따라 다양한 Gate 구조가 등장했는데, FinFET과 GAAFET도 이러한 Gate 구조 중 하나다.
FinFET 구조는 트랜지스터는 게이트와 채널간 접점이 클수록 효율이 높아진다는 점을 바탕으로, 핀 모양의 3D 구조를 적용하여 접점 면적을 증가시켜 트랜지스터의 성능을 향상시키고 누설 전류를 줄이는 방식이다. 채널의 상/좌/우 3면을 Gate가 둘러싸는 형태이다.
GAAFET는 수평 구조의 Gate에 채널을 수직으로 적층하는 방식이다. 채널을 나노와이어 형태로 설계하여 Gate가 이를 감싸는 형태로, 채널의 모든 면에 Gate electric field의 영향 미친다는 장점이 있다. 게이트와 채널의 접촉 면적이 넓어져 흐를 수 있는 전류의 양이 증가하며, 전류를 컨트롤 하기 쉬워지므로 칩의 성능개선이 가능하다.
FinFET은 인텔, TSMC, 삼성, 하이닉스 등에서 5nm, 7nm급 공정 소자에 사용되고 있으며, TSMC와 삼성 파운드리에서 3nm급 공정 소자에 GAA 공정이 도입된 바 있다. 삼성전자가 가장 먼저 GAA를 도입하여 3나노 공정 양산에 적용했으나, 여전히 수율확보에 어려움을 겪고 있으며 파운드리 실적 역시 부진한 상황이다.


*참고) GAAFET에서 Gate에 닿는 면적을 또한번 증가시킬 수 있는 구조가 MBCFET 구조이다. GAAFET 처럼 채널을 수직으로적층하는 것은 동일하나, MBCFET는 나노와이어 대신 나노시트를 사용하여 채널이 Gate에 닿는 면적을 늘렸다.

공정 변화에 따라 주목 받는 공법이 ALD(원자층 증착법)과 CMP(웨이퍼 평탄화 작업)이다.
1) ALD 공법
웨이퍼 위에 얇은 막을 쌓는 증착 공정에서 사용되는 공법 중 하나로, 칩의 크기가 작아지고 고집적화하면서 기존과 다른 더 미세하고 얇은 막이 필요해짐에 따라 도입된 방법이다. 기존 CVD 공법은 진공 공간과 웨이퍼 표면 모두에 화학 반응이 일어나거나 막이 쌓이지만, ALD는 프리커서(전구체)와 특정 반응 물질(리액턴트)를 반복적으로 주입해 웨이퍼 표면에서만 반응이 일어나기 때문에 막 두께를 절반으로 구현할 수 있다는 장점이 있다. 또 원자층 형성에 쓰이지 않는 원자는 튕겨져 나가기 때문에 기존 박막보다 일정한 굵기로 막을 형성할 수 있다. 따라서 반도체의 적층 단수가 증가할 수록 주목받는 기술이다.
장비: 원익IPS, 유진테크, 주성엔지니어링 등
2) CMP 공법
반도체 회로 공정(노광, 증착, 식각)을 하고나서 표면을 균일하게 만드는 작업으로, 칩 당 60~70번이 CMP 작업을 한다고 알려져 있다. (기계적) CMP 패드로 웨이퍼를 미세하게 갈아내는 과정에서 (화학적) 슬러리를 몇 방울 떨어뜨려 화학적 연마가 함께 이루어지도록 한다. CMP 공정은 반도체 회로 선폭이 미세화될수록 오염물질이 작아지면서 공정 횟수가 증가한다. (20나노 7회 -> 5나노 19회) 공정미세화, 적층 단수 증가로 인한 공정 횟수 증가로 CMP 공정 내 사용되는 연마제 슬러리 수요 증가가 기대된다.
장비: 케이씨텍(국내 유일 반도체 CMP 장비/소 국산화)
소재(슬러리): 케이씨텍(삼성전자), 동진쎄미켐(SK하이닉스), 솔브레인(삼성전자, SK하이닉스)
소재 측면에서는 High K 절연체와 Metal Gate가 주목받아 왔다.
반도체 전류의 양을 늘리기 위해서는 1) 채널 길이 단축 및 게이트 폭 증가 2) 전하 운반체 이동성 향상 3) 유전막의 capacitance 개선 필요하다.
이 중 유전막의 capacitance 향상시키기 위하여 사용하는 것이 High-K 물질이다. 유전막은 게이트 아래 위치한 얇은 절연막으로 게이트에 전압에 가해지면 채널에 있는 전하를 유전막 아래로 모아주는 역할을 한다. 유전막 아래에 더 많은 전하가 모일수록 전류의 양이 많아지는데, 유전상수가 높은 High-K 물질을 사용하면 유전율을 높여 전류의 양을 증가시킬 수 있으며, 이에 따라 같은 성능이더라도 유전막의 두께를 줄일 수 있다. 기존 SiO2의 유전상수가 3.9인데, Hf(하프늄) 기반 유전막의 유전상수가 24가 넘는 것을 보면 유전막 두께를 기존보다 1/6수준으로 줄일 수 있는 셈이다.
기존 SiO2 유전막은 실리콘을 산화시켜 증착하는 방식이었으나, High-K 절연막은 두께를 최소화하기 위해 ALD로 증착해야 한다는 차이점을 가진다. 반도체 전류의 양을 늘리기 위해 High-K 유전막 사용과 더불어, 메탈게이트를 이용하는 트랜지스터 구조를 도입했다. 이를 HKMG 구조라고 부르는데, 전력 소모를 줄이면서도 반도체의 성능은 유지하거나 향상시킬 수 있다.
참고: https://m.blog.naver.com/hanaseob/223202525558

2) 메모리 용량 H100 80GB, H200 141GB, B100 192GB로 메모리 용량 증가
B100은 1TB/s의 대역폭을 지원하는 24GB HBM3e 메모리가 8단으로 적층되어 192GB의 메모리를 사용한다.
슈퍼칩인 GB200은 Grace CPU 1개와 Blackwell GPU 2개로 구성되어 메모리가 두 배로 늘어난다. 메모리 용량이 증가할 수록 처리할 수 있는 데이터의 양과 속도도 증가하는 것이므로, 자연히 AI 서버 개발에 힘쓰는 빅테크로부터의 주문이 증가할 수 밖에 없다.
지난 10월 모건스탠리는 젠슨 황과 회의를 진행했는데, 회의 내용에 따르면 엔비디아의 블랙웰 주문이 향후 12개월 치가 이미 매진된 상태이다. 마이크로소프트, 구글, 메타, 아마존 등의 고객사들이 이미 엔비디아가 향후 1년 동안 생산할 예정인 차기 AI 반도체 블랙웰을 모두 구매한 것으로 알려졌다. 여전히 AI 반도체에 대산 수요는 견조함을 보여주는 지점이다.

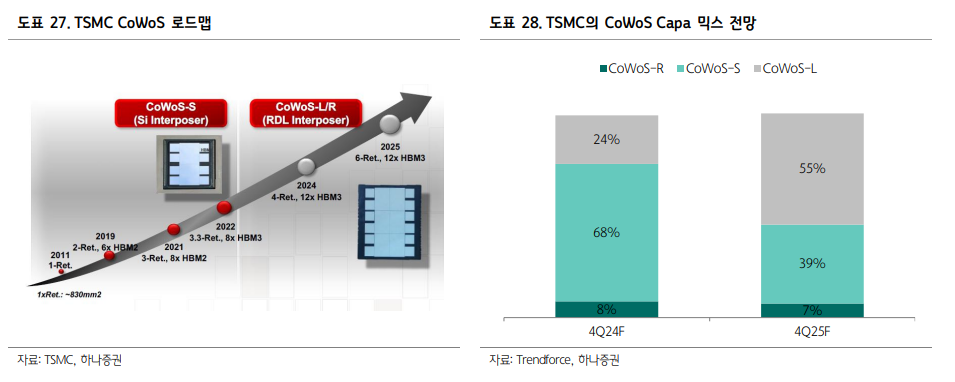
3) TSMC, CoWoS-L 패키징 도입
B100은 CoWos-L 패키징 기술이 도입되는 첫번째 주요 제품이다. TSMC의 2.5D 패키징 기술인 CoWoS(Chip on Wafer on Substrate)는 칩을 연결하는 방식에 따라(또는 인터포저에 따라) CoWos-S(silicon interposer), CowoS-R(RDL interposer), CoWos-L(LSI+RDL Interposer) 세 가지로 구분된다. 그 중 CoWoS-L은 칩의 제조 단가를 낮추기 위해 도입된 방법으로, 칩 전체를 덮는 풀사이즈 인터포저 대신 LSI라는 소형 인터포저를 사용하여 비용을 절감한다.
구체적으로 소형 LSI(Local Silicon Interconnect) 칩을 사용하여 다이와 다이 사이를 연결하는데, 이 때 칩과 칩을 연결하는 부위에만 브릿지 타입의 소형 인터포저를 배치한다. 높은 집적도와 성능을 제공하면서도 비용 효율성을 갖추고 있으므로 향후 TSMC의 패키징 capa중 CoWoS-L의 비중 점차 증가할 것으로 전망된다.
현재 TSMC의 CoWoS-L과 경쟁하는 브리지 칩 솔루션으로는 Intel EMIB, 삼성전자의 I-Cube, SPIL의 FO-EB, Amko의 SWIFT 등이 있으나 사실상 2.5D 패키징에서의 기술력은 독점적이며 인터포저도 TSMC가 제작하여 사용하고 있다.



| CoWoS-S | CoWoS-R | CoWoS-L | |
| 칩 연결 방식 | 실리콘 인터포저 | RDL(Redistribution Layer) 인터포저 - 유기물 기판 | LSI(Larger Scale Integration) + RDL |
| 장점 | 반도체 웨이퍼 제조 공정 사용 미세 가공이 가능하고 열팽창 계수 미스매치 발생 어려움 데이터 전송 속도가 가장 빠름 |
반도체 후공정 장비 사용 비용이 낮음 고주파 특성이 좋음 |
반도체 웨이퍼/후공정 제조 장비 사용 비용이 낮음 브릿지 부분 미세 가공 가능 |
| 단점 | 비용이 가장 높음 | 미세가공이 어려움 열팽창 계수 미스매치 발생 쉬움 |
브릿지의 다이시프트에 의한 수율 악화 브릿지 부분과 기판의 응력차 |
(자료: 하나증권, TSMC)
지난 10월 MS는 클라우드 컴퓨팅 플랫폼 Azure에 엔비디아 GB200 칩을 탑재했다고 밝히면서 엔비디아의 신제품 블랙웰을 최초로 도입했음을 공식화했다.
대만 폭스콘이 멕시코에 GB200 칩 제조를 위한 공장을 건설중이며, TSMC의 3nm 공정으로 생산
당초 4Q24 출시예정이었으나, 설계결함으로 생산이 지연된바 있음. 이후 패키징 공정 상 생산 수율을 높이기 위한 설계 변경이 이루어졌고, 10월 말에 Blackwell GPU 양산이 시작될 것이라고 보도됨. TSMC의 4나노 공정의 생산 주기가 약 3개월이므로 블랙웰 GPU 출시는 빨라도 내년 초로 지연될 것으로 예상됨.
(https://quasarzone.com/bbs/qn_hardware/views/1741746)
오픈IA, MS, 메타의 AI 제품 출시 현황 확인 -> GPU 사용 증가
빅테크에서 자체 칩 개발에 힘쓰고 있다고 하지만 MS, 아마존 등 주요 기업들이 여전히 엔비디아의 GPU를 사용 중인 것으로 알 수 있듯 시장 지위에서 여전히 독점적인 위치
Gate 공정 참고자료)
https://m.blog.naver.com/cjftjdqkr3/222533799631
[반도체소자] MOSFET 다양한 Gate(게이트) 구조 FinFET, GAAFET, MBCFET
MOSFET 다양한 Gate(게이트) 구조 안녕하세요 Valmet입니다. MOSFET이 다양한 Gate 구조를 ...
blog.naver.com
'Equity' 카테고리의 다른 글
| [반도체] 커스텀 반도체 (2) | 2025.02.05 |
|---|
